Development and Validation of ChatGPT Reliance Scale
Syeda Farhana Kazmi, Owais Ahmad, & Shamsa Siddique
Department of Psychology, Hazara University, Mansehra, Pakistan
As ChatGPT becomes more common in universities, many people are concerned about its effects on students’ learning, research quality, originality, and even procrastination habits. In response, this study developed and validated a detailed ChatGPT Reliance Scale for university students. The goal was to provide a reliable and accurate tool for capturing the complex ways students use ChatGPT in higher education. To this end, we conducted a cross-sectional survey of 1,000 students from various universities and postgraduate colleges in Abbottabad and Peshawar. An exploratory factor analysis (EFA) was performed on the first segment of the dataset, comprising 409 participants. The EFA indicated a three-factor structure that explained 61.99% of the total variance. A confirmatory factor analysis (CFA) was then conducted on the remaining 400 participants, supporting the three-factor model and yielding acceptable fit indices (?˛ (235) = 1074, p < .001; CMIN/DF = 4.57; CFI = 0.91; GFI = 0.91; RMSEA = 0.06). All factor loadings were statistically significant (p < .001) and ranged from 0.54 to 0.85. Overall, the scale demonstrated strong internal consistency (Cronbach’s a = 0.92, McDonald’s ? = 0.93), suggesting it is a reliable instrument for assessing how and to what extent university students rely on ChatGPT.
Keywords: ChatGPT, Higher Education, Reliance, Novelty, Procrastination, Artificial Intelligence.
Generative artificial intelligence (AI) is becoming part of everyday life, reshaping how people think, work, and learn. One of the best-known tools is OpenAI’s ChatGPT, widely used to generate human-like text, solve problems, summarize information, and provide interactive support across a range of domains (Zhou & Lee, 2024). As professionals and college students increasingly use ChatGPT in their academic and professional lives, it is increasingly important to understand how it affects their thoughts, feelings, and behavior.
ChatGPT provides university students with quick access to resources that can enhance efficiency and learning, including summaries, writing assistance, explanations, and coding support. However, this ease of use may lead to overreliance when students substitute AI for cognitive participation (Rudolph et al., 2024). In a similar spirit, employees, particularly knowledge workers, use ChatGPT to compose emails, prepare reports, give presentations, and brainstorm ideas. Workflows may be streamlined, but over time, opportunities for critical thinking and autonomous problem-solving may diminish. This growing reliance raises important concerns about users' relationships with generative AI with respect to productivity, autonomy, and self-regulation.
Reliance is a degree of dependence, and reliance on ChatGPT reflects the extent to which people rely on it to perform assigned tasks. Reliance on ChatGPT is fundamentally distinct from the frequency of use. It concerns the importance of ChatGPT in helping students complete an assignment. One student may routinely use ChatGPT alongside a literature search to develop assignment ideas, while another may use it only occasionally. However, for the latter student, ChatGPT may play a more important role in idea generation. Reliance on ChatGPT thus concerns the extent to which students regard it as fundamental to their learning activities (Stojanov et al., 2024). ChatGPT reliance entails regularly relying on ChatGPT for tasks you could do on your own. Although this behavior is shaped by ChatGPT’s conversational and generative design, it still aligns with what we know about cognitive offloading—using technology to think or remember for us (Risko & Gilbert, 2016; Rudolph et al., 2024).
Novelty, or the extent to which users are attracted to ChatGPT because of its perceived originality or distinctiveness, is a second dimension. This novelty can lead to heightened, sometimes shallow, use behaviors, especially among professionals and students using AI tools for the first time (Shin, 2021). A third and crucial element is procrastination, which occurs when users engage with ChatGPT excessively, either as a distraction or to avoid work or decision-making, thereby creating the appearance of productivity (Meier et al., 2023). According to one study, when people have a heavy workload, they are more likely to adopt and use technology. When faced with a heavy workload, students typically seek ways to cope. As a result, people use simple strategies or shortcuts (e.g., ChatGPT) to manage such stressful circumstances (i.e., excessive workload) (Abbas et al., 2024).
Currently, there is no well-established psychometric tool that systematically examines how university students and working adults use ChatGPT across these three areas. This gap persists despite growing concerns about the use of AI in academic and professional contexts. The present study aims to address this need by developing a multidimensional scale comprising three subscales: Reliance, Novelty, and Procrastination. The scale is intentionally designed to fit academic and workplace contexts and draws on ideas from digital behavior, cognitive psychology, and human–AI interaction.
This scale has practical value as well as research significance. In educational settings, it can help teachers and administrators understand whether students are using AI to replace their own effort and understanding or to support and extend their learning. When students exhibit high levels of dependence or procrastination, the scale can help identify them, enabling more targeted guidance or interventions. In professional environments, the scale can inform organizational decisions about productivity, digital well-being, and the responsible use of AI. Understanding the extent to which employees rely on AI can help managers distinguish between situations in which AI genuinely supports productivity and those in which it may undermine independent thinking or sound judgment.
From a research perspective, this tool provides a starting point for studying how the use of generative AI relates to outcomes such as self-regulation, digital literacy, learning performance, and job satisfaction. As AI systems become increasingly embedded in academic and professional routines, a reliable, well-validated measure of how people engage with ChatGPT is important. Such a measure can support efforts to promote ethical, effective, and balanced forms of collaboration between humans and AI.
Extended Mind Theory
This idea suggests that our thinking does not occur solely in our heads. It can also include the tools and technologies we use in our everyday environment. In this sense, ChatGPT can function as an extension of the mind, helping us generate new ideas by serving as an external semantic network or a brainstorming partner.
Runco and Jaeger (2012) describe creativity as the production of ideas that are both new and valuable. According to Extended Mind Theory, when someone uses a system such as ChatGPT as a thinking partner—by offloading memories, exploring possibilities, or seeking unexpected links—the interaction becomes part of that person’s own cognitive process. Because ChatGPT draws on a large and varied body of training data, it can offer ideas that spark connections users might not reach on their own. Recent work also suggests that using AI language models can enhance creative self-perception and support idea generation in tasks such as writing and problem-solving (Yeo, 2023).
Self-Determination Theory adds another layer to this discussion. It proposes that people are more motivated when they see themselves as competent and effective. ChatGPT can affect this in two different ways. On the one hand, it can help users understand complex concepts and complete tasks more efficiently, which may strengthen their sense of capability. On the other hand, if individuals routinely avoid effortful learning and lean too heavily on AI-produced answers, their skills may develop more slowly, and their competence may become fragile and dependent on access to AI (Deci & Ryan, 2017). In such cases, individuals may begin to credit the AI rather than their own abilities for successful outcomes, thereby undermining their sense of self-efficacy.
Dual-Process Theory (Thinking in System 1 and System 2)
According to Evans and Stanovich's (2013) Dual-Process Theory of Cognition, human thought processes are mediated by two systems, i.e., System 1: Fast, intuitive, and automated thought; and System 2: Analytical, laborious, and slow thinking.
System 1 is particularly well served by ChatGPT, which provides quick, easily assimilated outputs with minimal cognitive strain. Regular usage of ChatGPT may eventually train users—both professionals and students—to rely on fast AI-assisted responses rather than System 2's laborious cognitive processes. As users increasingly delegate problem-solving to AI, they become less engaged in deeper learning or analytical reasoning, resulting in greater reliance on AI (Rudolph et al., 2024).
p>Extension of the Technology Acceptance Model (TAM)Davis's (1989) Technology Acceptance Model identifies perceived usefulness and perceived usability as the primary determinants of new technology acceptance. Reliance on ChatGPT is fueled by perceived usefulness ("ChatGPT helps me get things done more efficiently"). Engagement is increased by interactive novelty and ease of use, especially in the early phases of exposure.
To account for novelty-driven usage, newer versions of TAM, such as TAM 3 (Venkatesh & Bala, 2008), also consider hedonic motivation, curiosity, and habit. Because of its captivating design, ChatGPT's uniqueness as a state-of-the-art conversational and generative tool increases initial attraction and sustained use (Shin, 2021).
Theory of Cognitive Offloading
Risko and Gilbert (2016) describe cognitive offloading as the act of reducing the mental effort we expend internally by turning to external tools, including digital technologies. In many ways, ChatGPT functions like an always-available external brain: users employ it to assist with tasks such as reading, generating summaries, brainstorming ideas, and drafting emails or written responses.
While this kind of offloading can make work feel easier and more efficient, it may also lead to growing dependence and habitual use. When people rely on ChatGPT too often rather than engaging directly with their tasks, this can encourage procrastination and a form of digital avoidance (Meier et al., 2023). To examine these patterns more systematically, the ChatGPT Reliance Scale (CRS) has been developed as a psychometric tool that captures how and to what extent users rely on ChatGPT across cognitive, behavioral, and emotional domains. In this context, reliance refers to the extent to which students perceive ChatGPT as necessary for their learning activities. Their level of knowledge about the tool and their attitudes toward it not only shape whether they adopt it but also how frequently they use it. More broadly, in the field of artificial intelligence (AI), students’ AI literacy and their views about ChatGPT help predict how they use it and, in turn, how strongly they come to depend on it for tasks (Uppal & Hajian, 2024).
The CRS, therefore, offers a way to assess patterns of reliance on ChatGPT, and these patterns have important consequences. In educational settings, higher scores on this scale may be linked to weaker self-regulation, lower academic engagement, and less robust learning outcomes. In professional settings, heavy reliance on ChatGPT for routine or instrumental tasks may boost productivity in the short term, but over time, it could limit opportunities for skill development and independent decision-making.
Method
A cross-sectional survey methodology was used to verify the ChatGPT reliance scale. The participants in the study were from higher education institutions, such as universities and postgraduate colleges. Data were collected from nearly 1000 individuals across various universities and doctoral colleges in Abbottabad and Peshawar. This resulted in a response rate of 22.22%, which surpassed the minimum of 10 participants per item required for scale development and validation. After removing incomplete and missing data, the final sample included 809 participants- 500 females (61.8%) and 309 males (38.2%).
The participants' mean age was 21.96 years (SD = 2.21; range = 18-26). The study required that participants be enrolled in a higher-degree program, such as a bachelor's or master's program. Furthermore, students from schools and intermediate colleges were excluded from the study because they do not have regular access to ChatGPT for their studies and assignments.
Measures
The ChatGPT Reliance scale, designed and validated exclusively for this study, served as the study's primary instrument. The Scale comprises 45 items in total, assessing three aspects of students: reliance, novelty, and procrastination. Items were developed based on different theories mentioned in the introduction, experts in the fields had formal discussions, and those discussions led to an item pool with each subscale consisting of 15 items. All items were scored on a 5-point Likert scale, with responses ranging from strongly disagree to strongly agree. Scores are interpreted as follows: higher scores indicate greater reliance, novelty, and procrastination.
Procedure
Data were collected from participants within their university departments. Hard copies of questionnaires were delivered to participants, who were informed that there were no correct or incorrect responses. The researchers also advised them that participation in the study is entirely voluntary and that any participant may withdraw at any time. Furthermore, they were instructed to complete the questionnaire regarding their use of ChatGPT. They were also taught that it is the participants' ethical and moral obligation to fill out the questionnaire honestly and completely. The data-gathering procedure took more than two months because it was difficult to travel, obtain official authorization, and collect data from the appropriate pupils.
Furthermore, after collecting data from several institutions in Abbottabad and Peshawar, the data were cleaned, and incomplete, pattern-filled questionnaires were excluded, resulting in 809 participants' data being considered accurate. The research reported a 19% attrition rate.
Data Analysis
Following data clarification, the data were analyzed using SPSS version 30, and AMOS 23 was used to conduct the CFA. The data analysis procedure consisted of three major phases. The first phase involved checking the data's normality, analyzing its frequency distributions, and calculating the scale's overall reliability. Similarly, the overall convergent validity of the scale was assessed using two distinct measures of the same construct. Convergent validity for each subscale was also evaluated using multiple scales that measure the same components. Furthermore, the discriminant validity of the research measure was evaluated using two independent scales assessing the opposite construct. All reliabilities and validities were estimated to be at or above 0.85.
In the next step, the data were divided into two segments of 409 and 400 participants for EFA and CFA, respectively. Exploratory factor analysis (EFA) was used to determine the factorial validity of the 45-item scale. Cross-loading and items with poor loading are permitted. Principal component analysis with varimax rotation was employed. After the EFA, items with good factor loadings and a discrimination index of more than .35 were included in the final version of the scale, which became a 24-item scale in total, comprising 8 items per subscale.
Following EFA, the next stage was Confirmatory factor analysis (CFA) to assess model fit and the psychometric properties of the final 24-item scale. The sample comprised 400 participants; segment two was separated from the total sample of 809 participants. The goodness-of-fit indices chi-square, CFI, GFI, TLI, RMSEA, and SRMR were examined. Acceptable model fit criteria were CFI, GFI, and TLI > 0.90 and RMSEA < 0.08.
Results
The original 45-item ChatGPT Reliance Scale underwent an exploratory factor analysis (EFA). Based on the outcomes of this inquiry, the scale was modified to its final 24-item format. The 24-item scale was then further investigated. Table 3 presents the factor loadings, means, standard deviations, and item-total correlations for the 24 items of the scale. The EFA, which included principal component analysis and Varimax rotation, revealed a three-factor structure accounting for 61.99% of the total variance.

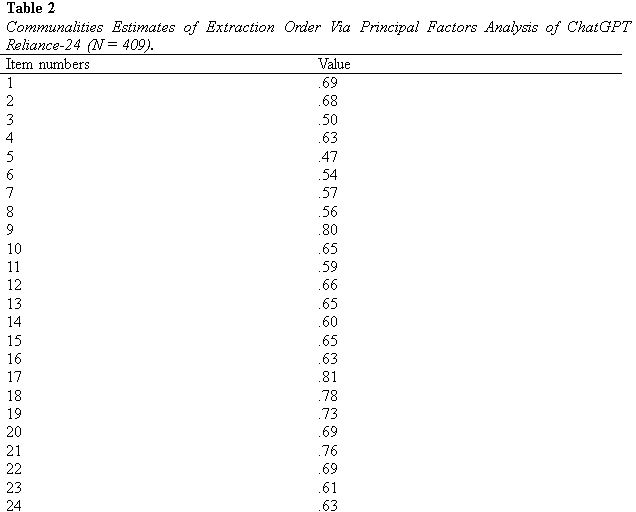



Table 4 presents the CFA results for the goodness-of-fit index (GFI) for the scale's three subscales. Appropriate figures for GFI (goodness-of-fit index), AGFI (adjusted goodness-of-fit index), CFI (comparative fit index), and IFI (incremental fit index) are .90 or higher, and the present analysis gained scores that are higher than .90. As a result, the present research provides substantial results. Cronbach's a, composite reliability, and convergent validity for the three factors are all excellent, as shown in Table 5.


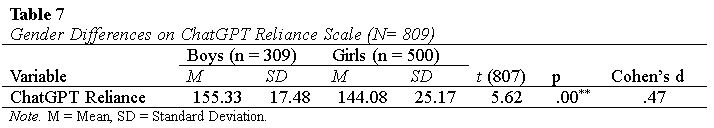


Item–total correlations were calculated to assess the extent to which each item was associated with the overall scale score. For items for which this information was available, correlations ranged from .39** to .58**, indicating moderate to strong relationships between individual items and the total scale. This pattern suggests that the items align well with the construct the scale is intended to measure.
The internal consistency of the scale was excellent, with Cronbach’s alpha of .92 and McDonald’s omega of .93. Data were gathered on several occasions and across multiple related measures from more than 220 participants to examine convergent and discriminant validity thoroughly. Convergent validity with the ChatGPT Usage Scale was strong (r = .85**). Convergent validity was also assessed using the General Attitude Towards Artificial Intelligence Scale, which includes two subscales: Positive Attitudes and Negative Attitudes. The ChatGPT Reliance Scale correlated positively with Positive Attitudes (r = .48**, p < .001) and negatively with Negative Attitudes (r = -.82**, p < .001), providing clear support for both convergent and discriminant validity.
Convergent validity was then examined at the subscale level. The Reliance subscale showed a positive correlation of .56** with a related construct. The Novelty subscale was positively associated with a creativity measure (r = .59**). The Procrastination subscale was positively related to an established student procrastination scale (r = .48**). Discriminant validity was further supported by a strong negative correlation with the Digital Well-Being Scale (r = -.85**). Overall, the reliability and validity indices were strong and comfortably exceeded commonly accepted benchmarks.
The three-factor structure identified in the exploratory factor analysis (EFA) was further tested using confirmatory factor analysis (CFA). In this model, the three components—Reliance (REL), Novelty (NOV), and Procrastination (PRO)—were specified as latent variables, and their respective items were treated as observed indicators (Fig. 1). The CFA results indicated a satisfactory model fit: ?2(235) = 1074, p < .001; CMIN/DF = 4.57; CFI = .91; TLI = .91; RMSEA = .06 (90% CI: .05–.066). All standardized factor loadings were statistically significant (p < .001).
Taken together, the EFA and CFA findings support a three-factor structure for the ChatGPT Reliance Scale—Reliance, Novelty, and Procrastination—and show that the scale has strong psychometric qualities, including good model fit, substantial factor loadings, and high levels of reliability and validity.

Discussion
This study aimed to develop and test a scale to assess how university students use, perceive, and experience ChatGPT. The analyses support a three-part structure for the ChatGPT Usage Scale, reflecting dependence, novelty, and procrastination. Overall, the scale shows solid psychometric qualities: the model fits the data well, factor loadings are strong, and reliability is high. Together, these findings suggest that the scale is a valuable tool for examining students' engagement with ChatGPT.
The first factor, Reliance, reflects the extent to which students rely on ChatGPT and their perceptions of this technology. It includes items assessing the extent to which they trust ChatGPT’s answers, how often they use it for feedback, and their awareness of its limitations. This aligns with prior work on technology use and confidence in automated systems. In this context, reliance refers to the extent to which students see ChatGPT as central to their learning tasks (Stojanov et al., 2024). Although shaped by ChatGPT’s interactive and generative nature, it also aligns with research on cognitive offloading, in which people shift mental work to external tools (Risko & Gilbert, 2016; Rudolph et al., 2024). Factor loadings for Reliance ranged from .57 to .72, indicating that many university students lean on ChatGPT for assignments and projects.
The second factor, Novelty, captures the extent to which working with ChatGPT encourages new ideas, perspectives, or approaches. Novelty tends to be higher when people use this type of tool for the first time, among both students and professionals (Shin, 2022). Items in this dimension assess whether ChatGPT helps students think in new ways or produce work that appears more original. Factor loadings for Novelty ranged from .54 to .80. These results are consistent with a preregistered study in which 77 university students completed ill-defined tasks: students with access to ChatGPT produced answers that were rated as more detailed (d = 0.61), higher in quality (d = 0.69), and more original (d = 0.55) than those in the control group (Urban et al., 2024).
Other work has examined creativity over longer periods. Liu et al. (2024) followed participants for 7 days and conducted a 30-day follow-up. Performance initially improved when ChatGPT was available but returned to baseline after its removal. The study also noted that ideas became increasingly similar over time—a pattern that persisted even after use ceased (Liu et al., 2024). In another study, Toma and Yáńez-Pérez (2024) tracked 31 students over 10 weeks. A little over half (53.6%) showed gains in creativity, 25% showed declines, and 21.4% showed no change. Taken together, these findings suggest that using ChatGPT does not necessarily harm creativity overall, though its impact may vary from person to person.
The third factor, Procrastination, addresses situations in which students turn to ChatGPT not to advance their work but to avoid it. In such cases, they may spend time exploring the tool, asking unnecessary questions, or repeatedly refining prompts, while feeling productive. This pattern aligns with earlier research showing that people under heavy workload are more likely to adopt technologies as a coping mechanism, sometimes by seeking shortcuts rather than tackling tasks directly (Meier et al., 2023; Reinecke et al., 2021; Abbas et al., 2024). In this study, the Procrastination factor was designed to capture the extent to which students delay their work because ChatGPT offers quick answers and ready-made solutions. As students become accustomed to instant help, they may delay initiating or completing tasks, assuming they can complete them later with the tool’s support. Factor loadings for this dimension ranged from .55 to .85. These results are consistent with theoretical arguments that the ease and speed of such tools can foster a ‘‘shortcut’’ mentality, in which students routinely postpone work because they believe they can complete it quickly later (Yilmaz, 2023).
Evidence from Pakistan reinforces this concern. An extensive survey of 494 participants, reported in Fast Company, found that heavy users of ChatGPT reported more procrastination, memory difficulties, and even lower GPAs. Another study with 113 university students in Pakistan found a significant positive association (r = .241, p = .010) between reliance on AI-based helpers (measured with the DAI scale) and self-reported procrastination. Mukhtar et al. (2025) therefore argue that overreliance on such technologies can lead to increased delays in work.
The three-factor model showed a good overall fit, as indicated by confirmatory factor analysis (CFI = 0.91; TLI = 0.91; RMSEA = 0.06). These indicators support the construct validity of the scale. In addition, reliability estimates were strong: composite reliability was 0.92, and McDonald’s omega (?) was 0.93, suggesting that the items within each factor measure closely related aspects of the same underlying constructs. When combined with evidence of content validity from the scale development process and factorial validity from both exploratory and confirmatory factor analyses, these findings support the ChatGPT Usage Scale as a sound and practical instrument for future research.
At the same time, several limitations need to be acknowledged. First, the sample was drawn from university and postgraduate students in Abbottabad and Peshawar. This focus may limit the extent to which the results can be generalized to other regions, cultures, or educational systems. Future research should test and refine the scale with students from a broader range of institutions and backgrounds to establish its suitability across contexts. Second, the study relied on self-report, which is always vulnerable to social desirability and other response biases—especially in an area where ethical questions about the use of AI in academic work are still actively debated. Later studies could address this by adding behavioral indicators, such as actual usage logs, or by combining self-reports with performance-based measures.
Finally, tools like ChatGPT are developing rapidly. New versions bring new features, interaction styles, and use cases. For this reason, the scale should not be viewed as fixed. It will need to be updated and revalidated regularly to ensure that it continues to reflect how students use these tools in their studies, and to enable researchers to track changes in patterns of dependence, novelty seeking, and procrastination over time.
References
Abbas, M., Jam, F. A., & Khan, T. I. (2024). Is It Harmful or helpful? Examining the Causes and Consequences of Generative AI Usage among University Students. International Journal of Educational Technology in Higher Education, 21(1). https://doi.org/10.1186/s41239-024-00444-7
Davis, F. D. (1989). Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology. MIS Quarterly, 13(3), 319–340. https://www.jstor.org/stable/249008
Deci, E. L., & Ryan, R. M. (2017). Self-Determination theory in work organizations: The state of a science. Annual Review of Organizational Psychology and Organizational Behavior, 4(1), 19–43. https://doi.org/10.1146/annurev-orgpsych-032516-113108
Evans, J. St. B. T., & Stanovich, K. E. (2013). Dual-Process Theories of Higher Cognition: Advancing the debate. Perspectives on Psychological Science, 8(3), 223–241. https://doi.org/10.1177/1745691612460685
Liu, Q., Zhou, Y., Huang, J., & Li, G. (2024). When ChatGPT is gone, creativity reverts and homogeneity persists. ArXiv (Cornell University). https://doi.org/10.48550/arxiv.2401.06816
Meier, A., Ine Beyens, S., T., J. Loes Pouwels, & Valkenburg, P. M. (2023). Habitual social media and smartphone use is associated with task delay among some, but not all, adolescents. Journal of Computer-Mediated Communication, 28(3). https://doi.org/10.1093/jcmc/zmad008
Risko, E. F., & Gilbert, S. J. (2016). Cognitive offloading. Trends in Cognitive Sciences, 20(9), 676–688. https://doi.org/10.1016/j.tics.2016.07.002
Rudolph, J., Mohamed, M., & Popenici, S. (2024). Higher Education’s Generative Artificial Intelligence Paradox: The Meaning of Chatbot Mania. Journal of University Teaching & Learning Practice, 21(06). https://doi.org/10.53761/54fs5e77
Runco, M. A., & Jaeger, G. J. (2012). The Standard Definition of Creativity. Creativity Research Journal, 24(1), 92–96. https://www.tandfonline.com/doi/abs/10.1080/10400419.2012.650092
Shin, D. (2021). The effects of explainability and causability on perception, trust, and acceptance: Implications for explainable AI. International Journal of Human-Computer Studies, 146(146), 102551. https://doi.org/10.1016/j.ijhcs.2020.102551
Stojanov, A., Liu, Q., & Hwee, J. (2024). University students’ self-reported reliance on ChatGPT for learning: A latent profile analysis. Computers and Education. Artificial Intelligence, 6, 100243–100243. https://doi.org/10.1016/j.caeai.2024.100243
Uppal, K., & Hajian, S. (2024). Students’ Perceptions of ChatGPT in Higher Education: A Study of Academic Enhancement, Procrastination, and Ethical Concerns. European Journal of Educational Research, 14(1), 199–213. https://doi.org/10.12973/eu-jer.14.1.199